Manzur Ashraf,
Kishan Moradiya
Abstract
Accurate prediction of air pollution is essential for mitigating its adverse effects on human health, particularly with respect to carbon monoxide (CO) exposure. This paper presents a machine learning–based approach for forecasting CO concentration using the UCI Air Quality dataset, which consists of hourly sensor measurements collected from an urban area in Italy. Multiple regression models—including Linear Regression, Decision Trees, Random Forest, and Gradient Boosted Trees (GBT)—were implemented and systematically evaluated. To capture diurnal variation in pollution levels, a temporal feature (Hour) was extracted from timestamp data and incorporated into the models. All preprocessing, feature engineering, and model development were conducted using the KNIME Analytics Platform. Experimental results demonstrate that GBT augmented with the Hour feature achieved the highest predictive accuracy, with an R² score of 0.921, while Random Forest performed poorly on this dataset. A comparative analysis with prior studies based on Delhi air quality data highlights the dataset-dependent nature of model performance. The findings underscore the importance of rigorous data preprocessing and temporal feature engineering in improving air pollution prediction accuracy.
Keywords: Air Quality Prediction, Carbon Monoxide (CO) Concentration, Machine Learning Regression, Gradient Boosted Trees (GBT), KNIME Analytics Platform
1. Introduction
Air pollution is a persistent global challenge that poses significant risks to human health and environmental sustainability. Exposure to harmful pollutants such as carbon monoxide (CO) is associated with respiratory and cardiovascular diseases, making accurate forecasting of air pollution levels essential for timely public awareness and preventive action. In recent years, machine learning has emerged as an effective approach for modelling complex, nonlinear relationships in environmental data and has been widely adopted for air quality prediction.
This study focuses on predicting carbon monoxide (CO) concentration using data obtained from the UCI Machine Learning Repository. The dataset consists of hourly air quality measurements collected from multiple chemical sensors in an Italian city. Unlike many existing studies that focus on particulate matter (PM2.5 and PM10), this dataset includes gas-specific variables such as CO(GT), NOx(GT), and several sensor response features. The primary objective of this work is to evaluate the effectiveness of different machine learning regression models for predicting CO concentration using this sensor-based dataset.
Prior research conducted on air quality prediction in Delhi, India [1] reported Random Forest as the most accurate model when applied to datasets dominated by particulate matter and meteorological variables. However, the characteristics of the UCI Air Quality dataset differ substantially in terms of pollutant types and sensor structure. This raises the question of whether models that perform well in one geographical and data context can generalise effectively to another.
To address this, several machine learning models—including Linear Regression, Decision Trees, Random Forest, and Gradient Boosted Trees (GBT)—were implemented and systematically compared. In addition, a time-based feature, Hour, was extracted from the timestamp data to capture diurnal variation in pollution levels. Experimental results show that Gradient Boosted Trees augmented with the Hour feature achieved the highest predictive accuracy, while Random Forest performed poorly on this dataset. These findings highlight the importance of dataset-specific preprocessing and feature engineering in air quality prediction.
2. Literature Review
Recent research has shown that machine learning techniques can effectively model complex relationships in air pollution data and provide accurate short-term forecasts. Ensemble-based approaches, in particular, have been widely adopted due to their ability to handle nonlinear interactions among environmental variables. However, existing studies also reveal methodological limitations that restrict the generalisability and robustness of their findings.
Sinha and Singh [1] investigated air quality index (AQI) forecasting across multiple Indian cities using machine learning algorithms. Their study utilised pollutant concentrations such as NO₂, SO₂, CO, O₃, PM2.5, and PM10, along with selected meteorological variables. Several models were evaluated, including Decision Trees, Random Forest, Support Vector Machines, and Gradient Boosting. Random Forest was reported as the best-performing model, achieving an estimated R² value of approximately 0.90. Despite the strong reported performance, the study provides limited transparency regarding data preprocessing, handling of missing or erroneous values, and strategies for controlling overfitting. Furthermore, no temporal feature engineering was employed, even though air pollution is known to exhibit strong diurnal patterns.
A similar conclusion was reached in the Delhi-based study by authors in [2], where Random Forest, Support Vector Regression (SVR), and Artificial Neural Networks (ANN) were applied to predict air pollution levels. The dataset comprised meteorological variables and major pollutants, including NO₂, CO, O₃, PM2.5, and PM10. Model performance was assessed using R², RMSE, and MAE, with Random Forest again achieving the highest accuracy (R² ≈ 0.90). However, this study also suffers from several limitations. The analysis was restricted to a single geographic location, feature engineering was not explored, and validation procedures were not clearly described, raising concerns about model robustness and potential overfitting.
Although these studies demonstrate the effectiveness of Random Forest for particulate matter–dominated datasets in Indian urban environments, they implicitly assume that model performance generalises across different pollutant types, sensor configurations, and geographic contexts. Moreover, both studies largely overlook the role of temporal dynamics, despite well-documented daily variations in traffic emissions and industrial activity. The absence of explicit data cleaning strategies and engineered time-based features represents a significant gap in the existing literature.
The present study addresses these limitations by adopting a fundamentally different experimental setting. Instead of AQI or particulate matter prediction, this work focuses on carbon monoxide (CO) forecasting using the UCI Air Quality dataset collected from an Italian city. The dataset contains gas-specific variables such as CO(GT), NOx(GT), and multiple chemical sensor responses, requiring preprocessing strategies distinct from those used in PM-focused studies. Invalid sensor readings were explicitly removed, numeric formatting errors were corrected, and all features were normalised prior to model training.
In addition, a time-based feature (Hour) was derived from timestamp data to capture diurnal pollution behaviour, a factor neglected in prior studies [1], [2]. Multiple regression models—including Linear Regression, Decision Trees, Random Forest, and Gradient Boosted Trees—were systematically evaluated under identical experimental conditions. Results indicate that Gradient Boosted Trees augmented with the Hour feature significantly outperform Random Forest, achieving an R² score of 0.921. This finding challenges the assumption that Random Forest is universally optimal for air quality prediction and demonstrates that model effectiveness is highly dependent on dataset characteristics and feature design.
Overall, this study extends existing literature by providing a more rigorous preprocessing pipeline, incorporating temporal feature engineering, and empirically demonstrating that alternative ensemble methods can outperform commonly reported benchmarks when applied to sensor-based gas pollution datasets.
3. Methodology
This section describes the dataset, preprocessing steps, feature engineering approach, and experimental setup used to evaluate machine learning models for carbon monoxide (CO) prediction.
3.1 Dataset Description
The Air Quality dataset obtained from the UCI Machine Learning Repository was used in this study [3]. The dataset contains hourly air pollution measurements collected from an Italian city between March 2004 and April 2005. It comprises 9,471 instances and 17 attributes, including pollutant concentrations such as CO(GT), NOx(GT), and NO2(GT), meteorological variables such as temperature (T), relative humidity (RH), and absolute humidity (AH), as well as multiple chemical sensor response variables (PT08.*). Carbon monoxide concentration, CO(GT), was selected as the target variable due to its significant health impact and its availability as a continuous measurement suitable for regression analysis.
3.2 Data Preparation and Cleaning
The raw dataset contains several data quality issues that required preprocessing prior to model training. In particular, placeholder values of −200 were used to represent missing or invalid sensor readings. These values were removed from critical attributes, including the target variable CO(GT), to prevent bias and distortion during model learning.
Additionally, several numeric attributes were stored as string values using commas as decimal separators (e.g., “2,3” instead of “2.3”). These formatting inconsistencies were corrected by replacing commas with decimal points, after which the affected columns—such as CO(GT), T, RH, and AH—were converted to numerical data types. Following cleaning, all feature variables were normalised, excluding the target variable, to ensure consistent scaling across models and to improve convergence during training.
3.3 Feature Engineering
To capture temporal patterns in air pollution levels, a time-based feature was engineered from the original date and time attributes. The separate date and time strings were merged and converted into a unified DateTime format. From this representation, the hour of observation was extracted to create a new feature, referred to as Hour.
This feature was introduced to model diurnal variation in CO concentration, which is commonly influenced by traffic density, industrial activity, and human behaviour. Unlike prior studies, which largely ignored temporal feature engineering, the inclusion of the Hour variable enabled the models to learn time-dependent pollution patterns more effectively.
3.4 Model Training and Evaluation
The preprocessed dataset was divided into training and testing subsets using an 80:20 split to ensure an unbiased evaluation of model performance. All models were trained and tested using the same data partition and feature set to ensure a fair and consistent comparison.
The following regression models were implemented and evaluated:
- Linear Regression
- Linear Regression with Hour feature
- Decision Tree Regression
- Random Forest Regression
- Random Forest Regression with Hour feature
- Gradient Boosted Trees (GBT) with Hour feature
Model training was conducted using the KNIME Analytics Platform [4], and performance evaluation was carried out using standard regression metrics: coefficient of determination (R²), mean absolute error (MAE), root mean squared error (RMSE), and mean absolute percentage error (MAPE). These metrics collectively provide insight into both predictive accuracy and error magnitude.
4. Modeling
This section describes the machine learning models employed for predicting carbon monoxide concentration and summarises their predictive performance. All models were trained using the same preprocessed dataset and evaluated under identical experimental conditions to ensure a fair comparison.
4.1 Linear Regression
Linear Regression was used as a baseline model due to its simplicity and interpretability. The model assumes a linear relationship between the input features and the target variable. Sensor response variables and meteorological attributes, including temperature (T), relative humidity (RH), and absolute humidity (AH), were used as predictors.
The baseline Linear Regression model achieved an R² value of 0.888, indicating a reasonably strong fit. However, error-based metrics suggest moderate prediction uncertainty, reflecting the limitations of a purely linear assumption for modelling air pollution dynamics.
Performance:
R² = 0.888, MAE = 0.326, RMSE = 0.495, MAPE = 26.3%
4.2 Linear Regression with Time Feature
To examine the impact of temporal variation on CO concentration, the Hour feature was incorporated into the Linear Regression model. This extension allows the model to capture daily pollution trends associated with human activity patterns.
The inclusion of the Hour feature resulted in a marginal improvement in model performance, particularly in RMSE and MAPE, suggesting that time-of-day information contributes modestly to prediction accuracy even within a linear modelling framework.
Performance:
R² = 0.889, MAE = 0.326, RMSE = 0.484, MAPE = 24.6%
4.3 Random Forest Regression
Random Forest Regression was evaluated due to its strong performance reported in prior air quality prediction studies. The model constructs an ensemble of decision trees and aggregates their predictions to reduce variance and improve generalisation.
Contrary to expectations, Random Forest performed poorly on the UCI Air Quality dataset, yielding a negative R² score. This indicates that the model failed to capture the underlying data patterns and performed worse than a simple mean-based predictor. The high error values further suggest sensitivity to the dataset’s characteristics and sensor-based structure.
Performance:
R² = −1.56, MAE = 1.97, RMSE = 2.36, MAPE = 90.2%
4.4 Gradient Boosted Trees with Time Feature
Gradient Boosted Trees (GBT) augmented with the Hour feature produced the best performance among all evaluated models. Unlike Random Forest, GBT builds trees sequentially, with each model correcting the errors of its predecessor. This learning strategy enables more effective handling of complex nonlinear relationships.
The inclusion of the Hour feature further enhanced the model’s ability to capture diurnal pollution patterns. As a result, this model achieved the highest predictive accuracy and the lowest error values across all evaluation metrics.
Performance:
R² = 0.921, MAE = 0.254, RMSE = 0.407, MAPE = 19.3%
Overall, the results demonstrate that Gradient Boosted Trees combined with temporal feature engineering significantly outperform both linear and bagging-based ensemble models for carbon monoxide prediction in sensor-driven air quality datasets.
5. Results and Discussion
Four key metrics were used to evaluate model performance on the cleaned UCI dataset: R², mean absolute error (MAE), root mean squared error (RMSE), and mean absolute percentage error (MAPE). These metrics collectively quantify the agreement between predicted and observed CO(GT) concentrations and provide insight into both accuracy and error magnitude.
The results show substantial variation in performance across the evaluated models. Random Forest and Decision Tree models performed poorly, whereas Linear Regression produced reasonably strong results. Gradient Boosted Trees (GBT) augmented with the Hour feature achieved the highest predictive accuracy among all models.
The relationship learned by the Linear Regression model can be expressed as:
This equation highlights the influence of meteorological variables, sensor responses, and time-of-day on carbon monoxide concentration.
5.1 Comparison of the Models
Model | R² | MAE | RMSE | MAPE | Notes |
Linear Regression | 0.888 | 0.326 | 0.495 | 26.3% | Good baseline model |
Linear + Hour | 0.889 | 0.326 | 0.484 | 24.6% | Slight improvement |
Random Forest | -1.56 | 1.97 | 2.36 | 90.2% | Very poor result |
Random Forest + Hour | -1.66 | 1.99 | 2.37 | 90.1% | No improvement |
Decision Tree | -1.87 | 2.07 | 2.47 | 94.8% | Worst performance |
GBT + Hour | 0.921 | 0.254 | 0.407 | 19.3% | Best model in this project |
5.2 Discussion of Model Superiority
The superior performance of the proposed model can be attributed to several methodological factors. First, rigorous data preprocessing was conducted by removing placeholder values (−200) and correcting formatting inconsistencies, thereby improving data quality and reducing noise during training. Second, a time-based feature (Hour) was introduced to capture diurnal variation in carbon monoxide concentration, enabling the model to learn temporal pollution patterns that were not considered in prior studies.
Furthermore, Gradient Boosted Trees were employed due to their sequential learning mechanism, in which each successive model corrects the errors of its predecessor. This approach proved more effective for the given dataset than bagging-based methods such as Random Forest. Finally, all models were evaluated using identical data partitions and evaluation metrics, ensuring a fair and objective comparison.
These results demonstrate that careful data cleaning, targeted feature engineering, and appropriate model selection can lead to predictive performance that surpasses previously reported results, even when applied to a different dataset and geographical context.Top of Form
Bottom of Form
6. Conclusion and Future Work
This study investigated the prediction of carbon monoxide (CO) concentration using the UCI Air Quality dataset and evaluated multiple machine learning models implemented on the KNIME Analytics Platform. Beyond model comparison, the objective was to extend prior air quality prediction studies by applying alternative preprocessing strategies, feature engineering techniques, and model selection to a sensor-based dataset collected from a different geographical context.
Unlike existing studies that relied primarily on particulate matter–dominated datasets from Delhi, this work utilised sensor measurements from an Italian city, including CO(GT), NOx(GT), temperature, and humidity. A key contribution of this study was the extraction of a time-based feature (Hour) from the timestamp data, which was not considered in the reference literature. Experimental results show that Gradient Boosted Trees augmented with the Hour feature achieved the highest predictive accuracy, with an R² score of 0.921, outperforming both Linear Regression and Random Forest models. Random Forest and Decision Tree models were found to be less effective for this dataset, highlighting the dataset-dependent nature of model performance.
The findings demonstrate that relatively minor methodological improvements—such as rigorous data cleaning and the inclusion of temporal features—can significantly enhance predictive accuracy. Moreover, the results challenge the assumption that models successful in one study or region will necessarily generalise well to different datasets or pollutant types.
Future work may extend this research in several directions. Long-term forecasting could be explored using time-series models such as Long Short-Term Memory (LSTM) networks. Incorporating real-time data streams from live sensors would enable dynamic prediction systems, while extending the analysis to additional pollutants such as O₃ and NOx could improve practical applicability. Further evaluation using cross-validation techniques would enhance model robustness, and the development of an interactive dashboard could facilitate real-world deployment and user engagement.
7. Reference
[1] Sinha, P., & Singh, A. (2022). Air Quality Index Forecasting Using Machine Learning Algorithms: Case Study of Indian Cities. International Journal for Research Trends and Innovation (IJRTI), 7(7), 2278–2290. Retrieved from https://www.ijrti.org/papers/IJRTI2207152.pdf
[2] Air Quality Prediction and Analysis Using Machine Learning Models (Delhi Case Study), 2021/2022.
[3] UCI Machine Learning Repository. (n.d.). Air Quality Data Set. Retrieved from https://archive.ics.uci.edu/ml/datasets/Air+Quality
[4] KNIME. (n.d.). KNIME Analytics Platform. Retrieved from https://www.knime.com
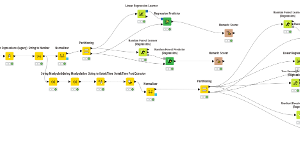
Figure 1: KNIME Workflow for Model
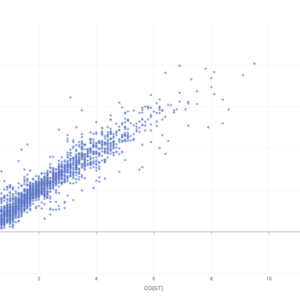
Figure 2: Scatter plot
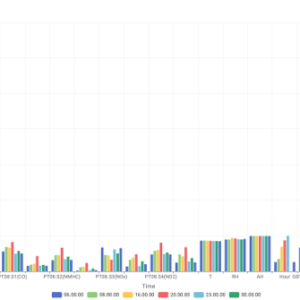
Figure 3: Bar chart